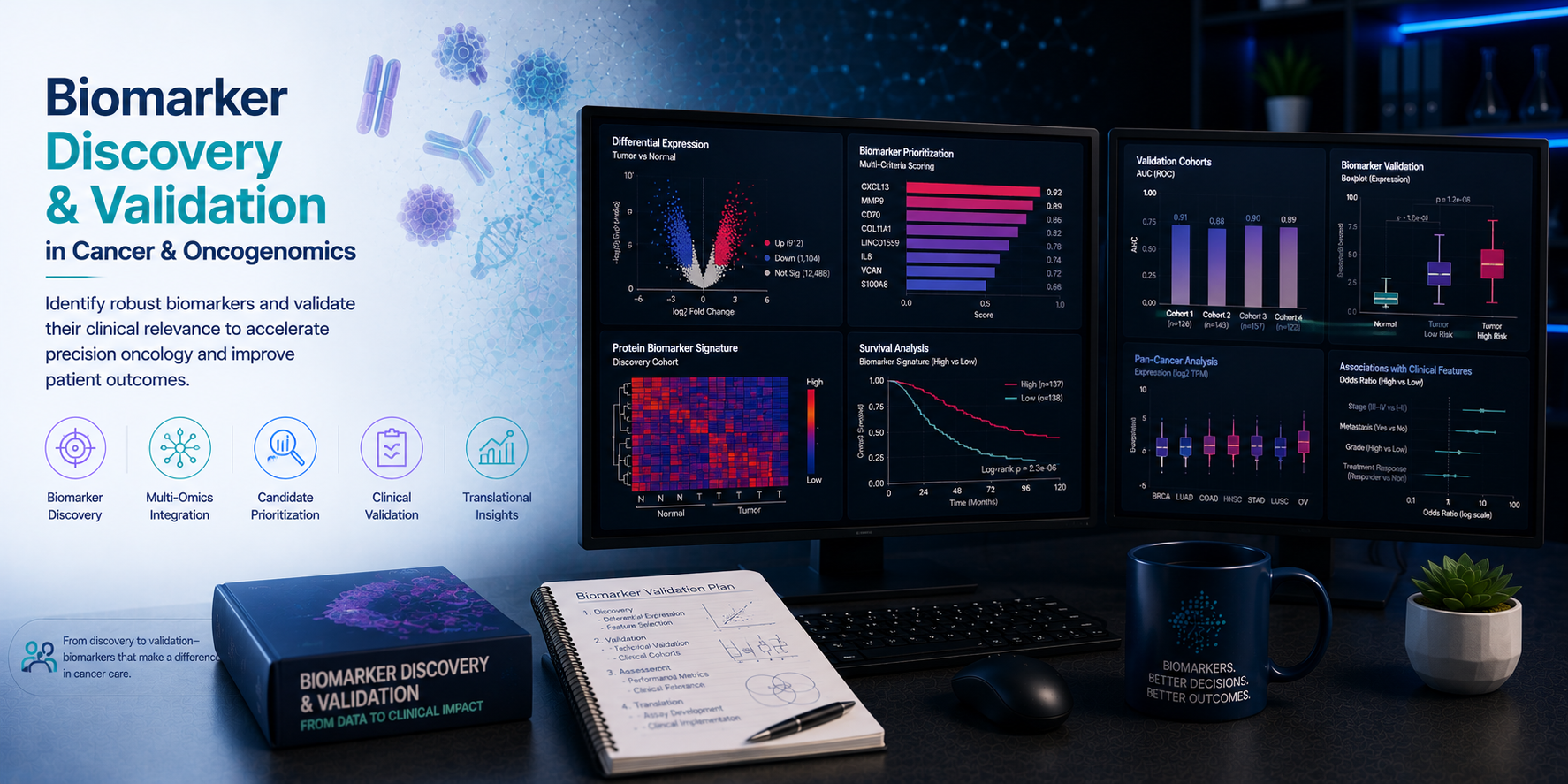
Biomarker discovery and validation is the translational bridge between biological insight and clinical impact — transforming genomic, transcriptomic, proteomic, and imaging data into robust, clinically validated markers that predict patient survival, guide treatment selection, stratify clinical trial populations, and support companion diagnostic development. From multi-omics cancer biomarker discovery and prognostic gene signature development to predictive response markers for immunotherapy and machine learning-based risk models, every stage of the biomarker pipeline demands rigorous bioinformatics and statistical expertise. At BioinformaticsNext, we provide specialist biomarker discovery and validation bioinformatics services — supporting academic cancer research groups, pharmaceutical clinical development teams, and diagnostic companies in identifying, developing, and validating cancer biomarkers from pre-clinical through to clinical datasets.
Biomarker Discovery & Validation: Cancer Biomarkers, Survival Markers & Predictive Signatures
Expert multi-omics biomarker discovery, prognostic gene signature development, immunotherapy response prediction, machine learning biomarker models, and clinical validation bioinformatics for oncology and precision medicine programmes.
The history of oncology is punctuated by transformative biomarkers — HER2 amplification directing trastuzumab therapy, PD-L1 expression predicting checkpoint inhibitor benefit, BRCA1/2 mutations conferring PARP inhibitor sensitivity, MSI-H status guiding pembrolizumab eligibility. Each of these began as a biological hypothesis that required rigorous computational analysis, cross-cohort validation, and clinical correlation to become a clinically actionable marker. The challenge today is not a lack of candidate biomarkers — it is the rigorous analytical framework to distinguish true signal from noise across heterogeneous patient populations, multiple omics layers, and conflicting datasets. At BioinformaticsNext, we provide the full biomarker discovery and validation bioinformatics stack — from initial multi-omics feature selection through signature development, independent cohort validation, and regulatory-grade reporting.
What We Support
Comprehensive biomarker discovery and validation bioinformatics across all omics modalities, cancer types, and clinical applications.
- Genomic biomarker discovery: somatic mutations, CNVs, TMB, MSI, and mutational signatures
- Transcriptomic biomarker panels and prognostic gene signature development from RNA-seq data
- Proteomic biomarker discovery from plasma, serum, and tissue mass spectrometry datasets
- Methylation and epigenomic biomarker identification from RRBS, WGBS, and array data
- Liquid biopsy biomarker development: ctDNA, cfDNA, and circulating tumour cells
- Immunotherapy response biomarker discovery from TME profiling and immune gene signatures
- Machine learning and AI-powered multi-omics biomarker model development
- Survival analysis and clinical outcome correlation across TCGA, GEO, and proprietary cohorts
- Cross-cohort biomarker validation and independent dataset replication
- Companion diagnostic and IVD analytical validation for regulatory submissions
Our Biomarker Discovery & Validation Services
Specialist biomarker bioinformatics across genomic, transcriptomic, proteomic, and multi-omics discovery platforms — with rigorous cross-cohort validation and regulatory-grade reporting.
All analyses are tailored to your cancer type, omics data modality, clinical endpoints, cohort design, and biomarker development objectives.
1. Genomic Biomarker Discovery & Tumour Mutational Profiling TMB · MSI · HRD · Somatic Variants · Signatures
Genomic biomarkers derived from somatic variant profiling, copy number analysis, and mutational signature decomposition are among the most clinically validated and therapeutically actionable cancer biomarkers — directly informing treatment selection, eligibility for targeted therapy, and immunotherapy response prediction.
- Somatic variant and oncogene profiling — Mutect2, Strelka2, and VarScan2 somatic variant calling from WGS, WES, and targeted panel data; oncogenic hotspot annotation with OncoKB and CancerVar; actionable variant identification against ESCAT, ESMO, and AMP/ASCO/CAP tiering frameworks
- Tumour mutational burden (TMB) and MSI scoring — TMB calculation calibrated to sequencing panel size and tumour type; MSIsensor, MANTIS, and MSIsensor-pro microsatellite instability scoring; harmonisation with FDA-approved companion diagnostic TMB thresholds for pembrolizumab eligibility
- Homologous recombination deficiency (HRD) scoring — CHORD, HRDetect, and scarHRD-based HRD scoring from WGS data; loss of heterozygosity (LOH), telomeric allelic imbalance (TAI), and large-scale state transitions (LST) component analysis; correlation with BRCA1/2 germline and somatic status
- Mutational signature biomarkers — SigProfilerExtractor COSMIC SBS, DBS, and ID signature decomposition; APOBEC, MMR deficiency, HRD, tobacco, and UV signature quantification as predictive biomarkers; signature-based treatment response prediction and clonal evolution tracking
2. Transcriptomic Biomarker Development & Prognostic Gene Signatures RNA-seq · LASSO · Survival · Cross-Cohort Validation
Gene expression biomarkers and multi-gene prognostic signatures derived from RNA-seq data represent the most established class of cancer biomarkers in clinical use — from Oncotype DX and MammaPrint in breast cancer to GEP-70 in myeloma and Decipher in prostate cancer. We provide the full bioinformatics pipeline for prognostic and predictive gene signature discovery, development, and cross-cohort validation.
- Differential expression and biomarker candidate discovery — DESeq2 and edgeR differential expression analysis between clinical groups; limma-voom for microarray and low-count RNA-seq data; univariable survival association testing for all expressed genes; false discovery rate-controlled candidate prioritisation
- Prognostic signature development — LASSO, elastic net, and ridge regression-based feature selection from RNA-seq survival data; stepwise Cox proportional hazards model development; risk score calculation and patient stratification into high- and low-risk groups; Kaplan-Meier survival curve generation and log-rank testing
- Predictive response signature development — Immunotherapy response gene signature development (T cell inflamed GEP, IFN-γ response, TGF-β exclusion signatures); chemotherapy and targeted therapy response transcriptomic predictors; signature validation against TIDE, CIBERSORT, and published immunotherapy response datasets
- Cross-cohort validation and generalisation testing — Independent validation of discovered signatures across TCGA, GEO, METABRIC, ICGC, and proprietary clinical trial cohorts; batch effect correction and normalisation harmonisation; signature performance metrics (C-index, AUC-ROC, NRI, IDI) across independent datasets
3. Proteomic & Liquid Biopsy Biomarker Discovery Plasma Proteomics · ctDNA · cfDNA · Olink · Mass Spec
Circulating biomarkers — from plasma proteins and cell-free DNA to circulating tumour DNA and exosomal cargo — offer the clinical advantage of non-invasive, longitudinally accessible sampling that is transforming cancer monitoring, minimal residual disease detection, and early detection. We provide specialist bioinformatics for plasma proteomics, ctDNA analysis, and liquid biopsy biomarker development.
- Plasma and serum proteomics biomarker discovery — MaxQuant, Perseus, and DIA-NN-based quantitative proteomics analysis; limma and DEqMS differential abundance testing; Olink proximity extension assay (PEA) NPX data analysis; ROC curve performance assessment and candidate biomarker panel development
- ctDNA and cfDNA liquid biopsy analysis — Ultra-deep targeted sequencing ctDNA variant detection (ichorCNA, MAESTRO, ctDNA-specific callers); ctDNA tumour fraction estimation; longitudinal ctDNA burden tracking for treatment response monitoring and minimal residual disease (MRD) detection
- Methylation-based liquid biopsy biomarkers — cfDNA methylation profiling with RRBS and WGBS; tissue-of-origin deconvolution from plasma cfDNA methylation patterns; CancerSEEK and DELFI-style fragment-based early detection biomarker analysis
- Biomarker panel optimisation — Multi-marker logistic regression model development combining proteomics, ctDNA, and clinical variables; panel size optimisation for clinical utility vs. cost trade-off; bootstrap-based internal validation and confidence interval estimation
4. Machine Learning & Multi-Omics Biomarker Models LASSO · Random Forest · XGBoost · Multi-Omics · AI
Single-omics biomarkers capture only a fraction of the biological complexity determining patient outcome. Machine learning integration of genomic, transcriptomic, proteomic, epigenomic, and clinical data enables multi-omics biomarker models that substantially outperform single-layer approaches in prediction accuracy, clinical utility, and generalisability across patient populations.
- Multi-omics data integration — MOFA+, mixOmics, and DIABLO-based supervised multi-omics integration; late, early, and intermediate fusion strategies for combining genomic, transcriptomic, and proteomic biomarker layers; feature importance analysis across omics modalities
- Machine learning biomarker model development — Random forest, gradient boosting (XGBoost, LightGBM), LASSO Cox, and deep neural network survival models; nested cross-validation for unbiased performance estimation; SHAP-based feature importance and model interpretability for clinical translational relevance
- Immune biomarker and TME signature models — CIBERSORTx, TIMER, and EPIC immune cell fraction estimation from bulk RNA-seq; TME immune score development; multi-variable models combining immune composition, mutational landscape, and clinical covariates for immunotherapy response prediction
- Model calibration and clinical utility assessment — Hosmer-Lemeshow calibration testing; decision curve analysis (DCA) for net clinical benefit assessment; number needed to treat (NNT) and clinical impact curve analysis; comparison of model utility against standard-of-care clinical risk scores
5. Survival Analysis & Clinical Outcome Correlation Cox · Kaplan-Meier · C-index · TCGA · GEO · Validation
Rigorous survival analysis and clinical outcome correlation is the final and most critical step in translating a candidate biomarker into a clinically actionable marker. We apply appropriate statistical frameworks for time-to-event data, multivariate confounding adjustment, and independent cohort validation — ensuring that biomarker claims are statistically robust, biologically credible, and clinically meaningful.
- Kaplan-Meier and Cox proportional hazards analysis — OS, PFS, DFS, and RFS survival endpoint analysis; univariable and multivariable Cox regression with clinical covariate adjustment; proportional hazards assumption testing; restricted mean survival time (RMST) analysis for non-proportional hazards settings
- Optimal cutpoint determination — MaxStat, Youden index, and median-based cutpoint selection; correction for multiple testing in data-driven cutpoint optimisation; pre-specified vs. exploratory cutpoint distinction for regulatory-grade analyses
- TCGA, GEO, and public cohort integration — Systematic curation and harmonisation of TCGA, GEO, METABRIC, PCAWG, and ICGC clinical and molecular data; cross-cohort meta-analysis of biomarker prognostic performance; forest plot visualisation of hazard ratios across independent validation cohorts
- Subgroup and interaction analysis — Pre-specified subgroup analyses by histological subtype, stage, treatment, and molecular class; biomarker-by-treatment interaction testing for predictive vs. prognostic marker distinction; forest plot-based subgroup hazard ratio reporting
Key Applications
Biomarker discovery and validation bioinformatics across cancer types, therapeutic contexts, and clinical development stages.
- Prognostic gene signature development for breast, lung, colorectal, and prostate cancer
- Immunotherapy response biomarker discovery from TME and mutational profiling
- PARP inhibitor, CDK4/6 inhibitor, and targeted therapy companion biomarker development
- Liquid biopsy ctDNA and plasma proteomics biomarker discovery for early detection
- Clinical trial biomarker strategy and patient stratification endpoint development
- Multi-omics ML risk model development for personalised oncology decision support
- IVD and CDx analytical validation for FDA and CE-IVD regulatory submissions
- Cross-cohort biomarker meta-analysis and independent validation studies
Tools, Technologies & Reference Databases
Validated, clinically proven bioinformatics tools and all major cancer biomarker reference resources.
- Transcriptomics: DESeq2, edgeR, limma-voom, GSEA, clusterProfiler, singscore
- Survival Analysis: survival, survminer, timeROC, survcomp, RTCGA, coxme
- ML Biomarker Models: glmnet, caret, XGBoost, scikit-learn, SHAP, pROC
- Multi-omics: MOFA+, mixOmics, DIABLO, iCluster, SNF
- Somatic/TMB/MSI: Mutect2, SigProfiler, MSIsensor, CHORD, HRDetect, scarHRD
- Proteomics: MaxQuant, Perseus, DIA-NN, DEqMS, MSstats, Olink NPX analysis
- Liquid Biopsy: ichorCNA, MAESTRO, cfDNA methylation pipelines, DELFI
- TCGA / GEO / METABRIC / ICGC — Major cancer genomic and transcriptomic cohorts for biomarker validation
- OncoKB / CancerVar / CIViC — Clinical variant and biomarker actionability databases
- TIDE / CIBERSORT / TIMER — Immunotherapy response and immune cell fraction reference tools
Project Deliverables
Structured, publication-ready biomarker discovery and validation outputs for every project.
- Ranked biomarker candidate list with effect sizes, p-values, and FDR-adjusted q-values
- Prognostic gene signature with risk score formula, patient risk group assignments, and survival plots
- Kaplan-Meier survival curves with log-rank p-values and median survival by biomarker group
- Multivariable Cox regression results with hazard ratios, confidence intervals, and forest plots
- Cross-cohort validation performance summary: C-index, AUC-ROC, NRI, and IDI across datasets
- ML model performance report: accuracy, AUC-ROC, precision-recall, calibration, and SHAP plots
- Publication-ready figures (PDF/SVG/PNG at 300 dpi): Kaplan-Meier, volcano plots, forest plots, ROC curves
- Full written scientific report with methods, results, interpretation, and clinical context
- IVD and CDx analytical validation documentation for FDA and CE-IVD regulatory submissions
- Decision curve analysis and clinical utility assessment for regulatory and HTA submissions
- Manuscript methods section and supplementary data (journal-formatted)
- Grant application biomarker discovery and validation sections with preliminary data
- Clinical trial biomarker strategy document and SAP biomarker analysis plan
- Long-term retainer for ongoing cohort expansion and prospective validation support
Frequently Asked Questions
Common questions from cancer research groups, pharmaceutical clinical development teams, and diagnostic companies.
A prognostic biomarker predicts patient outcome — such as survival or recurrence — independent of treatment received. A predictive biomarker predicts differential benefit from a specific treatment compared to an alternative. The distinction is clinically critical: a prognostic marker identifies high-risk patients regardless of therapy, while a predictive marker identifies which patients will benefit from a specific drug. We apply appropriate statistical tests for each — univariable and multivariable survival association for prognostic markers, and biomarker-by-treatment interaction testing in randomised datasets for predictive marker validation.
Sample size requirements depend on the expected biomarker effect size, the frequency of clinical events, the number of candidate features being tested, and the validation strategy. As a general rule, discovery cohorts of fewer than 100 patients with limited events are prone to overfitting and unstable feature selection. We advise on power calculations, minimum event requirements, and appropriate cross-validation and validation strategies at project scoping — and are transparent about the statistical limitations of smaller cohorts where these apply.
Yes. We routinely curate, harmonise, and analyse TCGA, METABRIC, GEO, ICGC, and PCAWG public datasets for independent biomarker validation. We apply appropriate batch correction, normalisation harmonisation, and clinical endpoint standardisation to ensure that cross-dataset validation reflects genuine biological generalisation rather than technical artefact. We also advise on which public datasets are most appropriate for your cancer type, biomarker modality, and clinical endpoint.
Yes. We assist with the bioinformatics and statistical methodology sections of clinical trial biomarker SAPs — including pre-specified biomarker cutpoint definition, multiple testing correction strategy, subgroup analysis plans, and the distinction between primary, secondary, and exploratory biomarker endpoints. Pre-specified biomarker analyses with documented analytical plans substantially strengthen the regulatory and scientific credibility of biomarker findings from clinical trials.
Yes. We produce analytical validation documentation — including sensitivity, specificity, reproducibility, and clinical performance assessments — suitable for FDA 510(k), De Novo, PMA, and CE-IVD IVDR companion diagnostic submissions. All biomarker analyses are delivered with full pipeline version control, methods documentation, and audit trail records required for regulatory submission compliance.
Related Research Areas & Services
Biomarker discovery and validation connects to multiple complementary services we support.
- Cancer & Oncogenomics — Somatic variant calling, TMB, MSI, HRD, mutational signature analysis, and neoantigen prediction providing the genomic layer of multi-omics cancer biomarker discovery
- Single-Cell RNA-seq: TME & Clonal Evolution — Single-cell immune profiling, cancer cell state mapping, and TME composition quantification as the basis for single-cell-informed biomarker development
- Spatial Transcriptomics — Spatially-resolved TME biomarker discovery including TLS scoring, immune exclusion quantification, and spatial gene expression biomarkers from tumour tissue sections
- Drug Development & AI-Driven Discovery — AI-powered companion biomarker development, patient stratification, and multi-omics integration for pharmaceutical drug development programmes
- Clinical Genomics & Variant Interpretation — Germline biomarker analysis, ACMG variant classification, hereditary cancer risk assessment, and IVD analytical validation for clinical biomarker programmes
- Custom Software & Pipeline Development — Bespoke biomarker analysis pipelines, automated survival analysis platforms, and clinical trial biomarker reporting tools for internal research and development teams
Ready to Advance Your Cancer Biomarker Programme?
Tell us about your cancer type, your omics data, your clinical endpoints, and your biomarker development objectives. Our biomarker discovery and validation team will design a tailored bioinformatics plan — typically within 48 hours of your enquiry. Whether you need prognostic gene signature development, immunotherapy response biomarker discovery, ctDNA liquid biopsy analysis, machine learning multi-omics risk models, or companion diagnostic validation support, we are here to deliver rigorous, publication-ready biomarker results from day one.
